Cambridge climate modeling AI case study: Aardvark Weather
The Cambridge climate modeling AI case study of Aardvark Weather chronicles a bold experiment: replace the traditional weather forecasting pipeline with an end-to-end, data-driven AI system trained on diverse observations. Researchers from the University of Cambridge, with collaborators at the Alan Turing Institute, Microsoft Research, and ECMWF, argue that this approach can deliver global forecasts on a coarser grid while outperforming several operational baselines and delivering local predictions with remarkable speed and efficiency. The implications stretch beyond academic curiosity: faster, cheaper, more accessible forecasts could reshape disaster preparedness, energy planning, and climate adaptation in data-sparse regions that historically rely on expensive infrastructure. The paper and supporting institutional releases place Aardvark Weather at the center of a Cambridge climate modeling AI case study that reporters and policymakers alike will watch closely as pilots scale. In the words of Cambridge researchers, the system is “thousands of times faster” and uses “thousands of times less computing power,” a claim that underscores the potential for democratized forecasting. (cam.ac.uk)
This Cambridge climate modeling AI case study unfolds at a moment when forecasting is both a scientific challenge and a public good. Traditional numerical weather prediction (NWP) relies on a sequence of tightly coupled models and data assimilation steps, run on specialized supercomputers. The Aardvark Weather project proposes a different path: train a single end-to-end model that ingests raw observations and outputs forecasts, reducing reliance on deployed NWP workflows. The authors illustrate that with an order-of-magnitude fewer observations and orders of magnitude less computational resources, the model can produce global forecasts that rival or exceed current baselines, while also delivering skillful local forecasts up to ten days ahead. This narrative—rooted in Cambridge’s environmental forecasting ambitions and backed by rigorous testing against established baselines—offers a concrete example of how AI can reshape climate science, policy, and practice. (nature.com)
Section 1: The Challenge
Data demands and the economics of forecasting
Forecasting the weather at scale is not just a scientific task; it is a financial and logistical one. NWP pipelines historically require dedicated supercomputing resources, long run times, and teams of scientists to maintain and validate the models. The Cambridge team framed the problem as two intertwined challenges: the high cost of traditional forecasting and the uneven access to computing power worldwide. In their own words and external summaries, Aardvark Weather aims to cut computational costs by orders of magnitude while preserving, and often improving, forecast quality. This is not simply an academic exercise; it is a blueprint for making high-quality forecasts more accessible to data-sparse regions and smaller organizations that lack large computational budgets. The Cambridge release and Nature paper emphasize that the end-to-end model can run on more modest hardware and still deliver global and local forecasts with competitive accuracy. (cam.ac.uk)
Accessibility and equity in weather intelligence
Aardvark Weather is positioned as a tool for democratizing forecasting, with potential benefits for agriculture, disaster risk management, energy planning, and public health. Cambridge press materials highlight that the approach could serve developing nations and data-sparse regions by eliminating the need for sprawling supercomputing infrastructure to generate useful forecasts. This framing reflects a broader policy objective: ensure reliable climate information is not limited by a country’s IT footprint. The collaborative nature of the project—linking Cambridge, the Alan Turing Institute, Microsoft Research, and ECMWF—also signals a cross-sector commitment to translating academic breakthroughs into practical, deployable systems. The researchers have framed deployment in the Global South as a near-term objective, contingent on pilots and partnerships that can adapt the model to local data availability and forecast needs. (cam.ac.uk)
Why previous approaches fell short or stalled
Prior to Aardvark, end-to-end data-driven weather forecasting was largely theoretical or demonstrated only in limited contexts. The Nature paper explicitly notes that while AI could replace individual components of the NWP pipeline, a fully end-to-end data-driven system had not yet been demonstrated at scale. The Cambridge work challenges that status quo by presenting a complete pipeline that learns directly from observations and can operate without reliance on deployed NWP products at prediction time. The paper also discusses the trade-offs and challenges of data heterogeneity, missing data, and the need for specialized training strategies to avoid instability or bias as the model scales. This candid assessment grounds the case study in real-world constraints and sets up the subsequent sections on approach and outcomes. (nature.com)
Section 2: The Solution
A three-module, data-first forecasting architecture
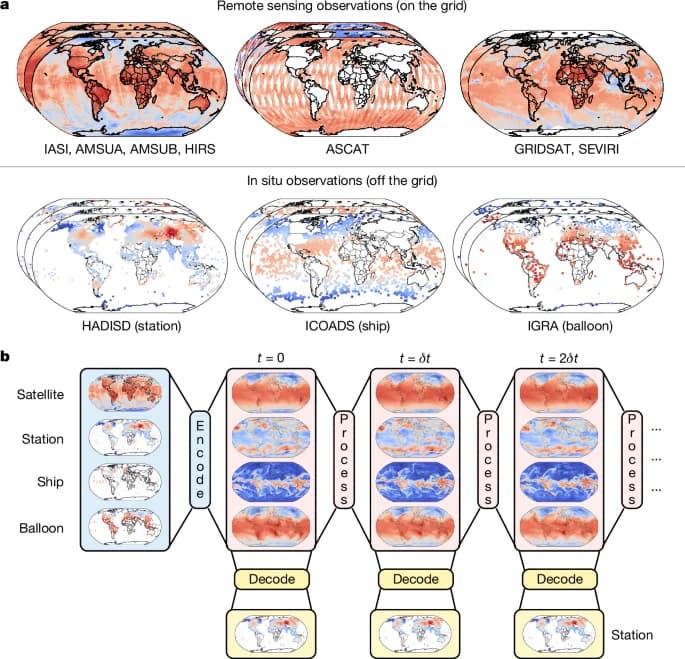
Aardvark Weather is designed as a modular neural process that stitches together encoder, processor, and decoder components. The encoder ingests a mix of gridded observations and off-grid data, producing an initial atmospheric state; the processor forecasts forward; and the decoder translates the internal state into gridded forecasts plus station-level predictions. The architecture is built on a vision-transformer backbone for the encoder and processor modules, with a lightweight convolutional decoder. This combination enables handling off-grid data and missing observations while preserving the capacity to produce forecasts at arbitrary locations. The configuration is deliberately designed to be trainable on ECMWF-era reanalysis data (ERA5) and then fine-tuned on sparser observational data, reducing the need for large, long-running datasets. The result is a system that can operate end-to-end, from raw observations to usable forecasts, without sacrificing the flexibility needed to adapt to local contexts. (nature.com)
Pretraining, fine-tuning, and data strategy
A key implementation detail is the staged training regimen. The team pretrains the encoder and processor modules on ERA5 reanalysis targets, then fine-tunes the full stack to match raw observational targets. This strategy addresses a central challenge in climate data science: observational records are often short and geographically uneven. By leveraging ERA5 for pretraining and then adapting to real observations, Aardvark reduces the risk of overfitting to sparse data while gaining generalization. The paper describes training across time-slices spanning 2018 for testing and 2019 for validation, with pretraining conducted over the years leading up to those test periods. This approach is a concrete, data-driven pathway for bridging high-quality retrospective data with real-world observational streams. (nature.com)
Training scope, data modalities, and integration
Aardvark’s inputs come from a diverse set of observational modalities: satellite radiances, scatterometer winds, hyperspectral sounders, infrared sounders, and in-situ observations from weather stations and radiosondes. This multimodal ingestion is essential for building a robust initial state and maintaining performance across atmospheric layers and regions. The model uses a grid representation with a resolution of 1.50 degrees for the global forecasts, a deliberate choice that balances computational efficiency with geographic coverage, while still enabling detailed downstream tasks. The approach demonstrates how modern AI architectures can integrate heterogeneous climate data streams into a single, trainable forecasting machine. (nature.com)
Timeline, collaboration, and the path to deployment
The Cambridge team describes an 18-month development cycle to build and validate Aardvark Weather, followed by ongoing work to extend deployment potential and partner with regional users. The Nature release and Cambridge communications note that the results have spurred plans to establish a team within the Alan Turing Institute to push deployment in diverse settings, including the Global South. This timeline underscores how academic breakthroughs can translate into practical tools for decision-makers and industries when supported by multi-institution collaboration and clear milestones. The collaboration brings together Cambridge researchers, the Alan Turing Institute, Microsoft Research, and ECMWF, reflecting a broad ecosystem approach to climate AI innovation. (cam.ac.uk)
Section 3: The Results
Global forecasts on a 1.50° grid outperform baselines
Aardvark Weather demonstrates that global forecasts generated from raw observations on a 1.50-degree grid can achieve lower RMSE than operational numerical weather prediction baselines for several variables and lead times. The study explicitly contrasts the end-to-end model against the GFS and high-resolution surrogates, noting that Aardvark matches or outperforms GFS in many cases, and approaches the performance of HRES for multiple variables. This result is particularly notable because it comes from training on far less observational data and with substantially less computational expense. The implication is a practical, off-the-shelf alternative to resource-intensive NWP for certain forecast needs. (nature.com)
Local station forecasts demonstrate tangible accuracy gains
Beyond global forecasts, Aardvark furnishes local station forecasts for 2-m temperature and 10-m wind speed, which are critical for health protections during heat waves and for energy and logistics planning in wind-heavy regions. The models’ local forecasts are shown to be skilful for lead times up to ten days, performing favorably against post-processed global NWP outputs and even beating fully end-to-end forecasting systems for several lead times. This finding addresses a core requirement of climate services: the ability to translate global patterns into actionable, local predictions. The results suggest a path to near-real-time local risk assessments that can inform public warnings, farmer decisions, and infrastructure planning. (nature.com)
Data efficiency and compute savings translate to ROI
One of the most consequential outcomes highlighted in the Cambridge climate modeling AI case study is the dramatic reduction in data and compute requirements. The Aardvark approach uses an order of magnitude fewer observations than operational baselines and orders of magnitude less computational resources, with the Cambridge release framing the model as tens of times faster and thousands of times more energy- and cost-efficient than conventional pipelines. In practical terms, this means faster turnaround for model iterations, lower energy footprints, and broader access for institutions without access to petascale computing. The combination of performance parity with baselines and substantial efficiency gains presents a compelling ROI argument for organizations exploring modern, AI-driven forecasting. (nature.com)
Timeline, trials, and near-term deployment opportunities
The results emerged from an 18-month development cycle, with testing on historical years (train on years before 2018, test in 2018, validate in 2019) and a direct path to applying the model to real-world data streams. The researchers explicitly frame deployment as an ongoing agenda, with plans to build out a dedicated team to push Aardvark toward field pilots in diverse environments, including the Global South. This emphasis on practical deployment complements the scientific results and demonstrates a commitment to turning a strong theoretical finding into policy-relevant practice. (cam.ac.uk)
The quality and limitations landscape
While the results are impressive, the authors acknowledge challenges common to end-to-end data-driven climate models. In longer lead times, forecasts can exhibit spectral blurring, and the model’s performance varies by atmospheric level and variable. The work also highlights the enduring importance of high-quality input data: ablation studies show that removing satellite data or in-situ measurements degrades performance, underscoring the value of diverse observational streams. These caveats are a natural part of translating a breakthrough into robust, operational tools, and they form the basis for ongoing refinements as deployment scales. (nature.com)
Section 4: Key Learnings
What worked well and why
-
End-to-end learning delivers speed, cost savings, and flexibility: replacing the traditional NWP pipeline with a single end-to-end model can dramatically reduce computation and data requirements while maintaining forecast quality. This is the core advantage highlighted by Aardvark and echoed in Cambridge’s public releases. The ability to train on ERA5 and fine-tune with real observations was a critical enabler for stability and generalization. The modular neural process architecture gave the system the flexibility to handle off-grid data and missing observations, a common feature of real-world climate data. The practical takeaway: when data is diverse and multi-source, an end-to-end design can unify disparate streams into a cohesive forecasting system. (nature.com)
-
Data strategy matters: pretraining on ERA5 before fine-tuning on observational data matters for performance and stability, particularly when on-grid data are sparse or irregular. This approach addresses the data scarcity problem that often limits climate AI projects. The training strategy is a vivid reminder that the path to robust climate AI is as much about data curation and training methodology as it is about model architecture. (nature.com)
-
Local utility is achievable with global models: the ability to generate reliable local forecasts (2-m temperature, 10-m wind) using a single end-to-end model demonstrates that AI-driven climate tools can extend from global pattern recognition to neighborhood-scale decision support. The local forecasts’ skilful performance up to ten days is a notable proof point that the model can be tuned for end-user needs beyond broad climate science. (nature.com)
What didn’t go perfectly and where to improve
-
Performance variability by variable and level: while Aardvark generally matched or outperformed baselines for many variables, some upper-atmosphere fields and certain lead times lag behind the strongest baselines. This nuance highlights that end-to-end AI is not a one-size-fits-all replacement for all aspects of the forecasting stack, and it may require region- and variable-specific tuning or hybrid approaches. The paper’s discussion of these limitations provides a realistic roadmap for incremental improvements rather than a blanket replacement. (nature.com)
-
Spectral blurring at longer lead times: when forecasts are extended far into the future, the model can become spectrally blurred, a phenomenon noted in the results. This underscores a broader truth in climate AI: longer horizons demand careful calibration and possibly multi-task or ensemble strategies to maintain sharpness and reliability. The authors’ transparency about this issue helps practitioners set appropriate expectations and design mitigation approaches. (nature.com)
Advice for others pursuing Cambridge-style AI climate case studies
-
Leverage diverse data streams and pretraining: combine remote sensing, in-situ measurements, and reanalysis data to create robust initial states and resilient predictions. The ERA5-pretraining strategy used by Aardvark provides a practical blueprint for other teams facing data-scarcity challenges. (nature.com)
-
Build for end-user impact from the start: design AI systems with local decision-making in mind. The value proposition isn’t only scientific; it’s about actionable forecasts for health, agriculture, energy, and emergency planning. The Cambridge program’s emphasis on station forecasts and real-world applications is a strong reminder of the importance of user-centric evaluation in climate AI. (nature.com)
-
Plan for equitable deployment: the collaboration and stated intent to deploy in the Global South show that researchers view climate AI as a tool for shared resilience, not a prestige technology. Early partnerships, pilots, and capacity-building will be essential to scale the benefits without leaving behind low-resource contexts. (cam.ac.uk)
Closing
The Cambridge climate modeling AI case study around Aardvark Weather offers a persuasive narrative about what happens when researchers pair end-to-end AI with rich, multi-source climate data. The results—global forecasts on a 1.50-degree grid that often beat incumbent baselines, plus highly useful local station forecasts—point to a future where fast, accessible, and reliable climate intelligence is within reach for a broader set of users. The project’s leaders emphasize practical deployment, and ongoing collaborations suggest that pilots and real-world deployments could emerge in the near term. If these efforts succeed at scale, the world could gain a more agile forecast system—one that helps communities prepare for climate variability, manage energy demand, and respond to weather-driven risks with unprecedented speed and precision. The Cambridge climate modeling AI case study thus stands as both a milestone in climate AI and a blueprint for how to move from breakthrough to broad utility.